
Blog Llama2 Md At Main Huggingface Blog Github
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with. Getting Started with LLaMa 2 and Hugging Face This repository contains instructionsexamplestutorials for getting started with LLaMA 2 and. Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the. Well use the LLaMA 2 base model fine tune it for chat with an open-source instruction dataset and then deploy the model to a chat app you can share with..
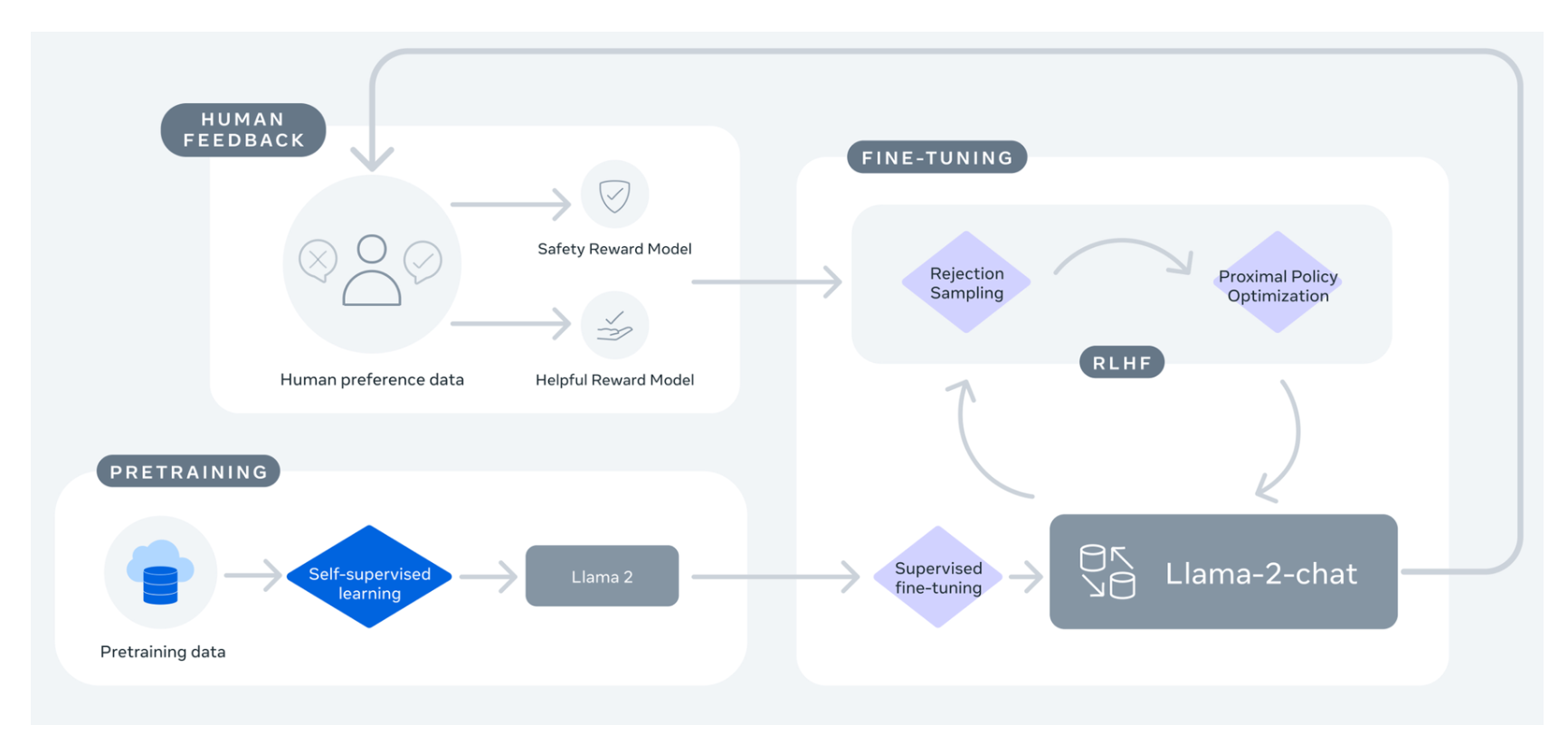
In this post well build a Llama 2 chatbot in Python using Streamlit for the frontend while the LLM backend is handled through API calls. Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets. In this tutorial well walk through building a LLaMA-2 chatbot completely from scratch. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction. Across a wide range of helpfulness and safety benchmarks the Llama 2-Chat models perform better than most open models and achieve..

Starfox7 Llama 2 Ko 7b Chat Ggml Hugging Face
Understanding Llama 2 and Model Fine-Tuning Llama 2 is a collection of second-generation open-source LLMs from Meta that comes with a commercial license It is designed to handle a wide. In this guide well show you how to fine-tune a simple Llama-2 classifier that predicts if a texts sentiment is positive neutral or negative At the end well download the model. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. The experience of fine-tuning on Paperspace by DigitalOcean In this blogpost we describe our in-practice experience of fine-tuning on Paperspace by DigitalOcean. The Llama 2 family of large language models LLMs is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters..
Today we are excited to announce the capability to fine-tune Llama 2 models by Meta using Amazon SageMaker JumpStart The Llama 2 family of large language models. This post was reviewed and updated with support for finetuning Today we are excited to announce that Llama 2 foundation models developed by Meta are. In this post we use QLoRa to fine-tune a Llama 2 7B model Deploy a fine-tuned Model on Inf2 using Amazon SageMaker AWS Inferentia2 is purpose-built machine learning ML. Lets dive into fine-tuning our own Llama-2 version Fine-tune Llama-2 with Amazon SageMaker The actual fine-tuning is done through an Estimator class that spins up a training. We currently offer two types of fine-tuning Instruction fine-tuning and domain adaption fine-tuning You can easily switch to one of the training methods by specifying parameter instruction_tuned..



Komentar